2. Hello World: Creating testable documentation
Let's assume you want to test and document the following
package example.helloworld;
/**
* Just print a hello.
* <p>
* This class doesn't do much, its only purpose is to print a
* message to <code>System.out</code> without any fuzz.
* </p>
*/
public class HelloWorld {
/**
* Prints "Hello World".
*/
public void sayHello() {
System.out.println(getMessage());
}
public String getMessage() {
return "Hello World!";
}
}
First, write a unit test method that checks the class:
@Test
public void testHelloWorld() {
HelloWorld hw = new HelloWorld();
assert hw.getMessage().equals("Hello World!");
assert hw.getMessage().endsWith("!");
hw.sayHello();
}
This unit test not only validates the correct behavior of the class, it also shows how the class is
supposed to be used. Traditionally, you'd now add a section in your software's manual, where you copy and
paste the code of the
With Lemma you don't copy/paste anything but write documentation as Javadoc on the test method in XHTML syntax:
/**
* The {@code HelloWorld} class
* <p>
* This is the source of the class:
* </p>
*
* <a class="citation"
href="javacode://example.helloworld.HelloWorld"/>
*
* <p>
* To use the class, first instantiate it, then call either {@code getMessage()} to retrieve
* the message string or {@code sayHello()} to print the message to {@code System.out}:
* </p>
*
* <a class="citation"
href="javacode://example.helloworld.HelloWorldTest#testHelloWorld"
style="include: HELLOWORLD_USAGE;"/>
*
* <p>
* If you don't want the message printed to {@code System.out}, don't call the
* {@code sayHello()} method.
* </p>
*/
@Test
public void testHelloWorld() {
HelloWorld hw = new HelloWorld(); // DOC: HELLOWORLD_USAGE
assert hw.getMessage().equals("Hello World!");
assert hw.getMessage().endsWith("!");
hw.sayHello(); // DOC: HELLOWORLD_USAGE
}
You probably already know all of the XHTML elements and attributes used in this Javadoc comment, in fact, you can
use any tags you need to write your documentation.
Lemma parses your markup and replaces the content of
]]> elements that have a
The second anchor is more specific, it's a citation for a fragment of code. The URL references the source of the
test class and the test method (yes, it's referencing "itself"). You'll probably recognize the method reference syntax
from Javadoc, it's the same as for regular Javadoc
The previous Javadoc represents just one small section of your overall documentation. Lemma's default processing
pipeline expects that you also create a master template file in XHTML that brings together all of your documentation
parts, chapters, and sections. How that template looks like, and how parts, chapters, and sections are organized and
finally rendered is up to you. Here is a simple example of a template:
Note that the URL scheme for this citation is
<?xml version="1.0" encoding="utf-8"?>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>My Manual</title>
<style xml:space="preserve" type="text/css">
.chapter .title {
font-size: 110%;
font-weight: bold;
}
.file .content, .javacode .content {
font-family: monospace;
white-space: pre;
margin: 15px;
padding: 5px;
border: 1px solid #aaaaaa;
background-color: #f0f0f0;
}
</style>
</head>
<body>
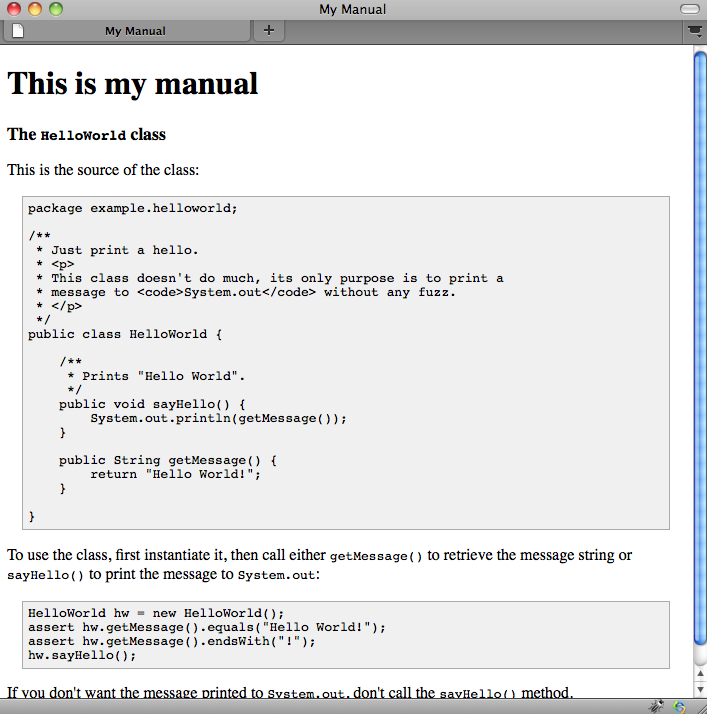
<div class="frontmatter">
<h1>This is my manual</h1>
</div>
<div class="chapter">
<div class="citation javadoc" id="javadoc.example.helloworld.HelloWorldTest.testHelloWorld..">
<div class="title">The <code><![CDATA[HelloWorld]]></code> class</div>
<div class="content">
<p>
This is the source of the class:
</p>
<div class="citation javacode" id="javacode.example.helloworld.HelloWorld">
<div class="content">
<pre class="prettyprint">package example.helloworld;
/**
* Just print a hello.
* <p>
* This class doesn't do much, its only purpose is to print a
* message to <code>System.out</code> without any fuzz.
* </p>
*/
public class HelloWorld {
/**
* Prints "Hello World".
*/
public void sayHello() {
System.out.println(getMessage());
}
public String getMessage() {
return "Hello World!";
}
}
</pre>
</div>
</div>
<p>
To use the class, first instantiate it, then call either <code><![CDATA[getMessage()]]></code> to retrieve
the message string or <code><![CDATA[sayHello()]]></code> to print the message to <code><![CDATA[System.out]]></code>:
</p>
<div class="citation javacode" id="javacode.example.helloworld.HelloWorldTest.testHelloWorld..">
<div class="content">
<pre class="prettyprint">HelloWorld hw = new HelloWorld();
assert hw.getMessage().equals("Hello World!");
assert hw.getMessage().endsWith("!");
hw.sayHello();
</pre>
</div>
</div>
<p>
If you don't want the message printed to <code><![CDATA[System.out]]></code>, don't call the
<code><![CDATA[sayHello()]]></code> method.
</p>
</div>
</div>
</div>
</body>
</html>
The formatting and indentation of this XHTML document has been automatically generated by a pretty printer, so it
readability could obvioulsy be improved. All Javadoc code fragments have been properly escaped in CDATA sections. All
cited source fragments have been escaped with XHTML entities instead (future versions of Lemma will likely embed
XHTML markup for callouts into code blocks, hence they are not defined as CDATA sections).
This is how it looks rendered in a browser: